
Elasticsearch
什么是全文搜索引擎?
百度百科中的定义: 全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
数据类型
从定义中我们已经可以大致了解全文检索的思路了,为了更详细的说明,我们先从生活中的数据说起。
我们生活中的数据总体分为两种:结构化数据 和 非结构化数据。
- 结构化数据: 指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据: 非结构化数据又可称为全文数据,指不定长或无固定格式的数据,如邮件,word文档等。
使用ES而不是数据库的原因
- 数据模型:数据库通常采用结构化数据模型,使用表格和列来组织和存储数据。ES则采用面向文档的数据模型,将数据存储为自包含的JSON文档。这使得ES更适合存储和搜索非结构化或半结构化的数据,如日志、文本文档、地理位置数据等。
- 搜索和分析能力:ES专注于全文搜索和实时分析,提供强大的搜索、聚合和分析功能。它使用倒排索引和分布式架构来支持高性能的搜索和复杂的查询操作。相比之下,传统数据库的搜索功能较为有限,对于大规模文本搜索和复杂的聚合查询可能效率较低。
- 弹性和扩展性:ES具有良好的水平扩展能力,可以轻松地通过添加节点来增加容量和吞吐量。它的分布式架构和自动分片机制使得数据可以并行处理和存储在多个节点上,从而实现高可用性和容错性。传统数据库在处理大规模数据和高并发负载时可能面临性能瓶颈和扩展困难。
- 实时性:ES提供近实时搜索能力,即文档索引后几乎立即可进行搜索。这使得ES适用于需要快速响应和实时更新的应用场景,如实时日志分析、监控和仪表盘。传统数据库通常具有更高的一致性和事务支持,但在实时性方面可能不如ES。
- 多种用例支持:ES广泛应用于全文搜索、日志分析、电子商务搜索、内容推荐、地理空间分析等多个领域。它提供了丰富的搜索、聚合和分析功能,以及与Kibana等工具的集成,使得数据探索和可视化更加便捷。传统数据库则更适用于事务处理、关系型数据管理和复杂的数据操作。
综上所述,选择使用ES而不是传统数据库的原因在于其强大的搜索和分析能力、良好的扩展性和实时性,以及适用于非结构化或半结构化数据的存储和检索需求。然而,具体选择何种技术取决于应用的特定需求和数据模型。在某些情况下,数据库和ES可以结合使用,以满足不同层次的数据管理和查询需求。
Elasticsearch vs Solr的选择
由于Lucene的复杂性,一般很少会考虑它作为搜索的第一选择,排除一些公司需要自研搜索框架,底层需要依赖Lucene。所以这里我们重点分析 Elasticsearch 和 Solr。
这两个搜索引擎都是流行的,先进的的开源搜索引擎。它们都是围绕核心底层搜索库 - Lucene构建的 - 但它们又是不同的。像所有东西一样,每个都有其优点和缺点,根据您的需求和期望,每个都可能更好或更差。Solr和Elasticsearch都在快速发展,所以,话不多说,先来看下它们的差异清单:
| 特征 | Solr/SolrCloud | Elasticsearch |
|---|---|---|
| 社区和开发者 | Apache 软件基金和社区支持 | 单一商业实体及其员工 |
| 节点发现 | Apache Zookeeper,在大量项目中成熟且经过实战测试 | Zen内置于Elasticsearch本身,需要专用的主节点才能进行分裂脑保护 |
| 碎片放置 | 本质上是静态,需要手动工作来迁移分片,从Solr 7开始 - Autoscaling API允许一些动态操作 | 动态,可以根据群集状态按需移动分片 |
| 高速缓存 | 全局,每个段更改无效 | 每段,更适合动态更改数据 |
| 分析引擎性能 | 非常适合精确计算的静态数据 | 结果的准确性取决于数据放置 |
| 全文搜索功能 | 基于Lucene的语言分析,多建议,拼写检查,丰富的高亮显示支持 | 基于Lucene的语言分析,单一建议API实现,高亮显示重新计算 |
| DevOps支持 | 尚未完全,但即将到来 | 非常好的API |
| 非平面数据处理 | 嵌套文档和父-子支持 | 嵌套和对象类型的自然支持允许几乎无限的嵌套和父-子支持 |
| 查询DSL | JSON(有限),XML(有限)或URL参数 | JSON |
| 索引/收集领导控制 | 领导者安置控制和领导者重新平衡甚至可以节点上的负载 | 不可能 |
| 机器学习 | 内置 - 在流聚合之上,专注于逻辑回归和学习排名贡献模块 | 商业功能,专注于异常和异常值以及时间序列数据 |
核心概念
- 索引(Index):索引是ES中存储和组织数据的逻辑容器。它类似于关系数据库中的数据库,可以包含多个类型(Type)。
- 类型(Type):类型是索引中的逻辑分类,用于定义相似结构的文档集合。从ES 7.0版本开始,类型已经被弃用,都使用默认类型_doc,推荐使用单一索引多个字段来代替。
- 文档(Document):文档是ES中的基本数据单元,以JSON格式表示。每个文档都有一个唯一的ID,并且属于特定的索引和类型(如果使用旧版本)。
- 映射(Mapping):映射定义了索引中文档的结构和字段的类型。它类似于关系数据库中的表结构定义。
- 查询(Query):查询是用于搜索和过滤文档的方式。ES提供了丰富的查询语法和功能,包括全文搜索、精确匹配、范围查询等。
- 聚合(Aggregation):聚合是对文档进行分组和计算的操作,类似于关系数据库中的GROUP BY和聚合函数。它可以用于生成统计数据、分析结果等。
- 节点(Node):节点是ES集群中的一个实例,负责存储和处理数据。一个ES集群可以由多个节点组成,每个节点可以承担不同的角色,如主节点、数据节点、协调节点等。
- 集群(Cluster):集群是由多个节点组成的ES环境,共同协作来存储和处理数据。集群提供了高可用性、容错性和水平扩展能力。
与数据库的比较
| ES概念 | 关系型数据库 |
|---|---|
| Index(索引)支持全文检索 | Database(数据库) |
| Type(类型) | Table(表) |
| Document(文档),不同文档可以有不同的字段集合 | Row(数据行) |
| Field(字段) | Column(数据列) |
| Mapping(映射) | Schema(模式) |
搜索与查询
- 全文搜索 Match Query:用于执行全文搜索,根据指定的字段和关键词匹配文档。它会对关键词进行分析,并返回与关键词最相关的文档。
- 精确匹配 Term Query:用于精确匹配,根据指定的字段和值查找完全匹配的文档。它不会对值进行分析,而是直接进行精确匹配。
- 范围查询 Range Query:用于在指定的范围内搜索文档。你可以指定数值、日期或字符串的范围条件,以获取满足条件的文档。
- 布尔查询 Bool Query:用于组合多个查询条件,支持逻辑操作符(must、must_not、should)。通过布尔查询,你可以构建复杂的查询逻辑。
- 过滤器 Filtered Query:结合查询和过滤器,用于同时执行查询和筛选操作。过滤器可以提高查询性能,因为它们不需要计算相关性,只需判断文档是否满足条件。
- 短语匹配查询 Match Phrase Query:类似于Match Query,但要求关键词作为短语完整匹配。它可以更精确地匹配短语,而不仅仅是单个词项。
- 前缀查询 Prefix Query:用于根据指定字段的前缀匹配文档。它可以用于搜索以特定前缀开头的词项。
- 通配符查询 Wildcard Query:支持通配符匹配,允许在查询中使用通配符(*和?)来模糊匹配文档。
- 模糊查询 Fuzzy Query:用于执行模糊匹配,根据指定字段和模糊度参数查找与关键词相似的文档。它可以处理拼写错误或近似匹配的情况。
- 嵌套查询 Nested Query:用于在嵌套对象中执行查询。它允许你在嵌套的文档结构中搜索和过滤数据。
- 聚合查询 Aggregation Query:聚合是对文档进行分组和计算的操作。ES提供了各种聚合函数,如求和、平均值、最大值、最小值等。聚合可以用于生成统计数据、分析结果和构建可视化报表。
原理
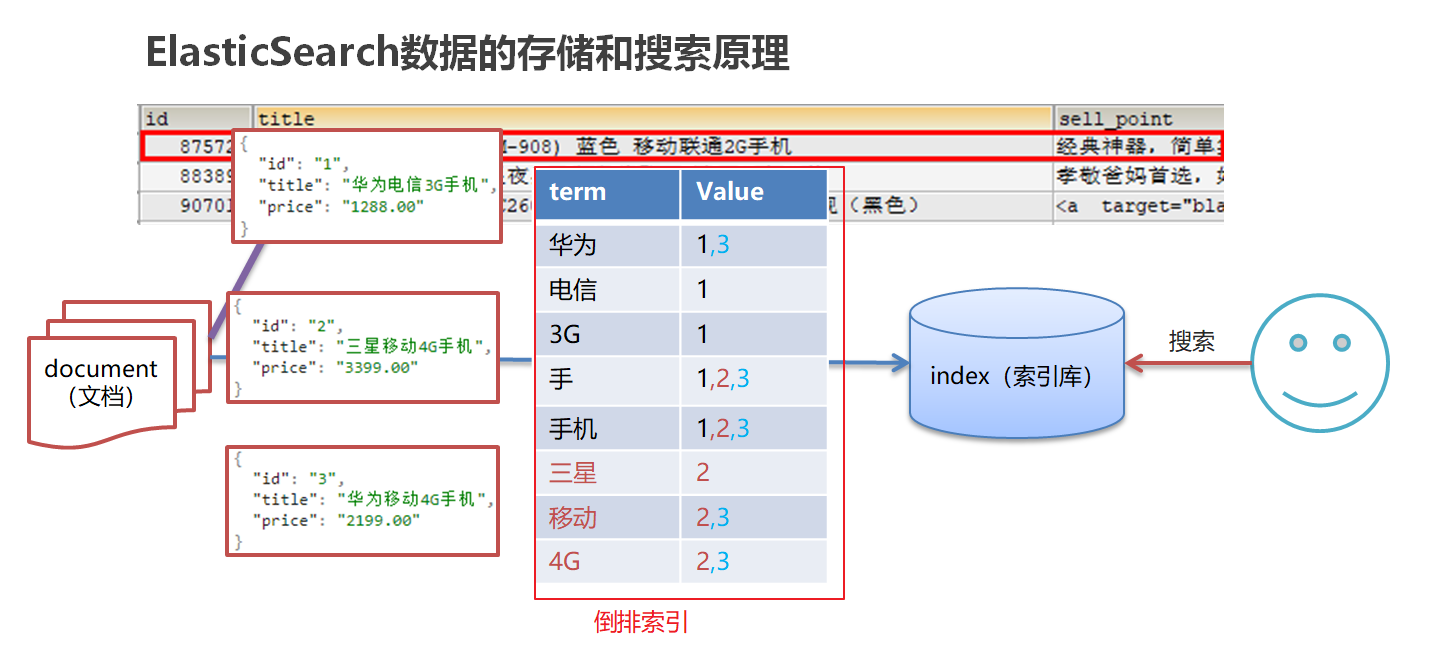
倒排索引
计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这种建立索引的方式叫倒排索引。
如下图所示,查询”华为”会得到对应的value=1和3,再通过1和3找到id=1和3的文档。
分布式集群
存储数据和搜索的节点可以是 “数据 (data)” 节点,执行更多管理任务的节点可以称为 “主 (master)” 节点;当主节点挂掉时,那么一个从节点自动变成主节点。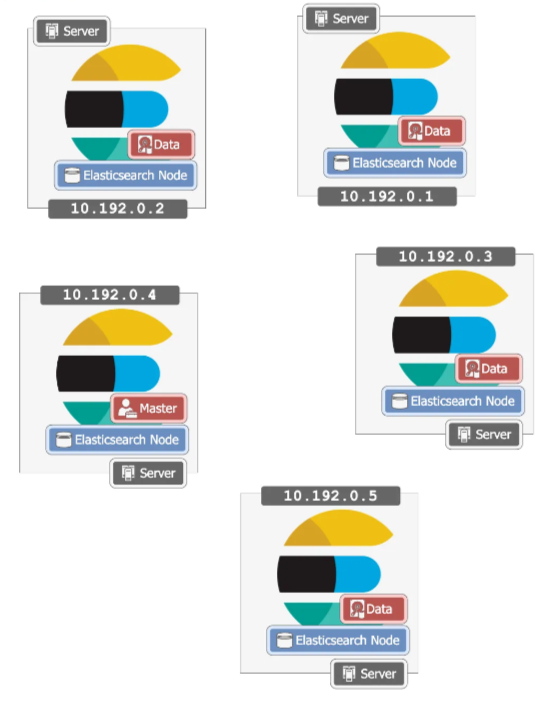
分片控制(Shards)
索引在ES中被分成多个分片,每个分片可以存储一部分数据。分片允许数据在集群中分布和并行处理。每个分片可以有多个副本,分为主分片(Primary)和副本分片(replica),用于提供冗余和高可用性。副本可以分布在不同的节点上,以防止单点故障。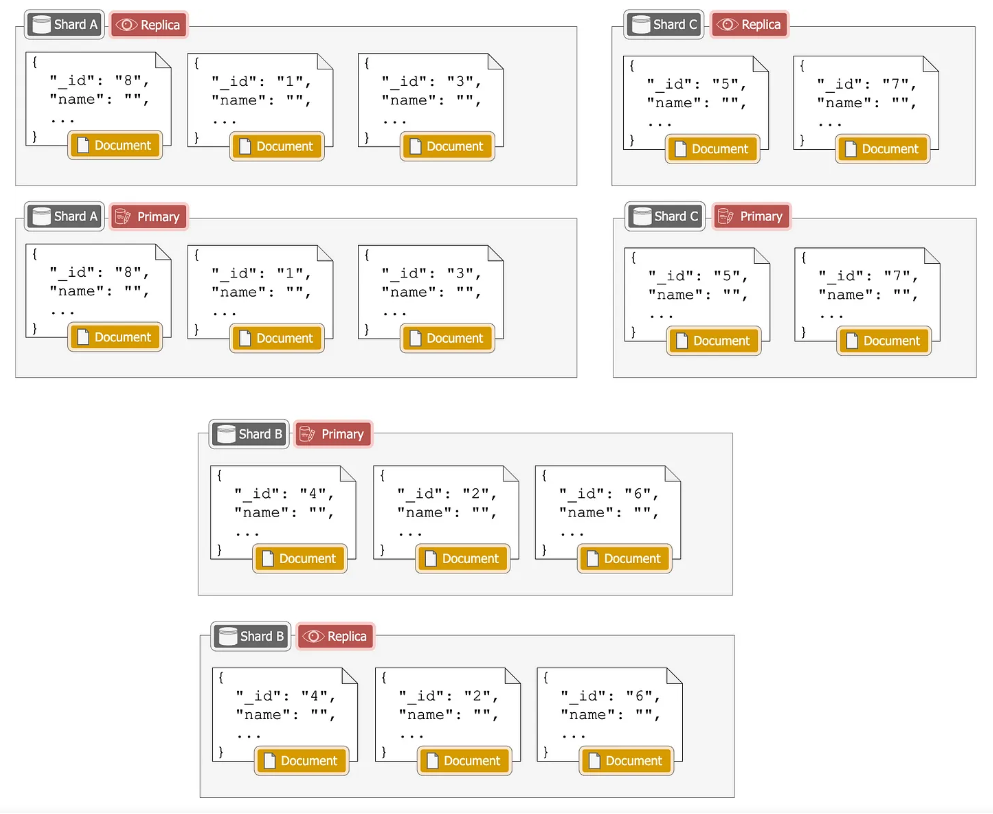
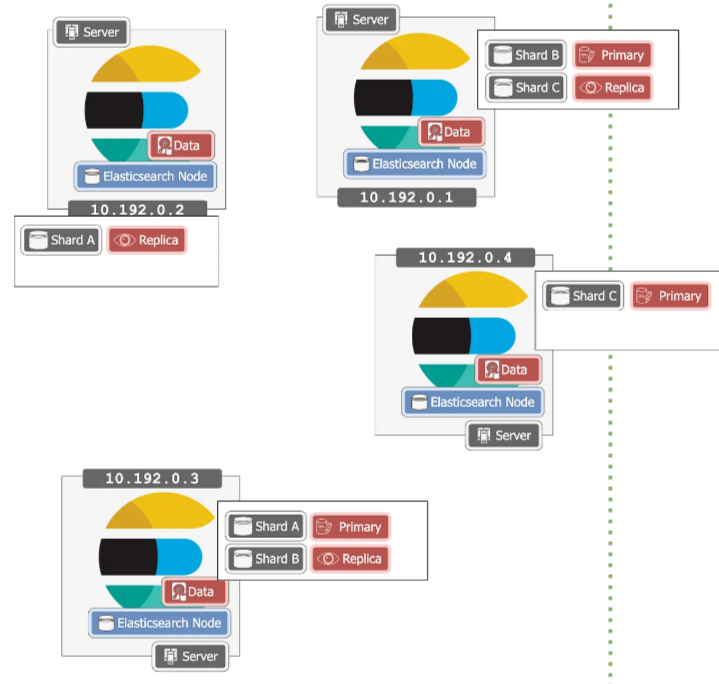
如果有多台机器故障,还是会导致某个主分片和副本分片丢失,我们还可以配置更高的复制,例如,每个主分片使用两个副本来缓解这种情况。
路由和均衡
当文档被插入到ES中时,它会根据文档ID和路由规则确定将文档存储在哪个分片上。ES使用一致性哈希算法来决定文档与分片之间的映射关系。这样文档可以均匀地分布在整个集群中,实现负载均衡。
协调节点
当执行搜索或查询操作时,客户端将请求发送到协调节点(协调请求),该节点将协调并将请求转发给包含相关数据的分片。每个分片独立地执行查询,并将结果返回给协调节点,最后由协调节点汇总和排序结果。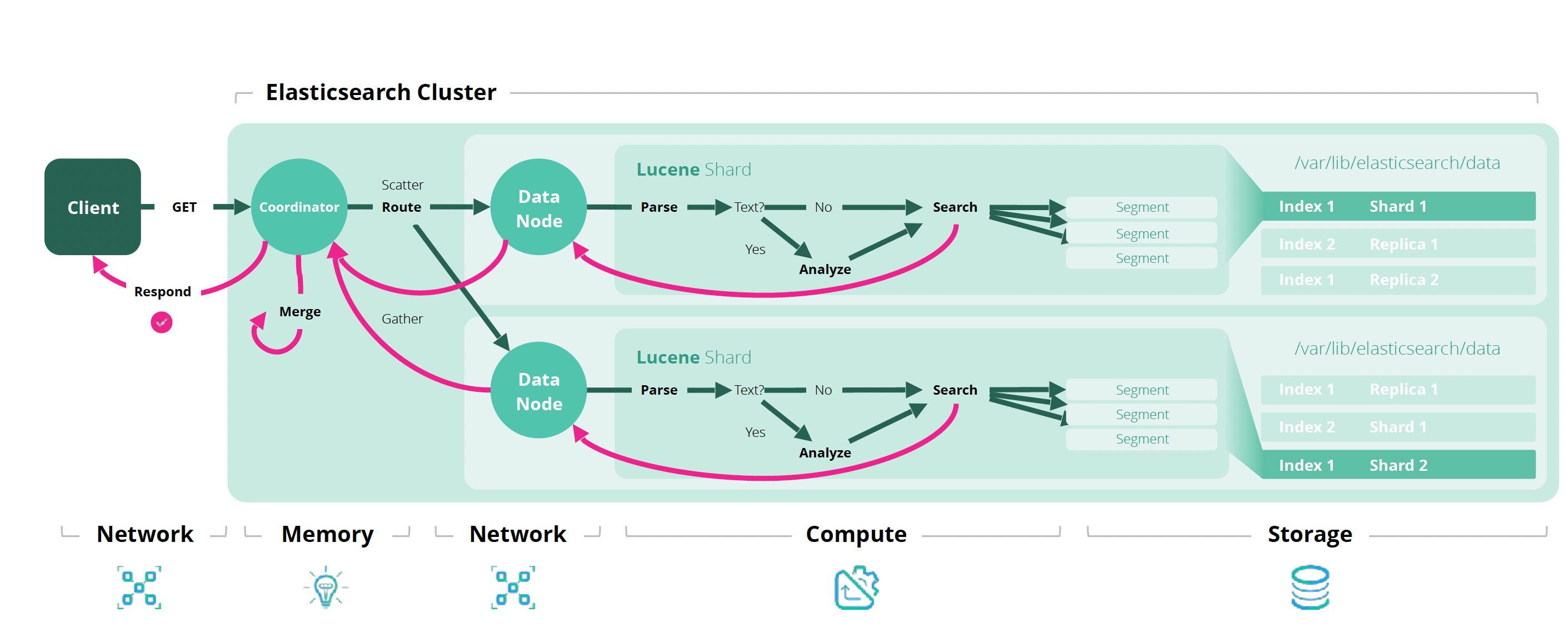
文档写入
假如选择了Node2(DataNode)发送请求,此时Node2称为coordinating node(协调节点)
计算得到文档要写入的分片
shard = hash(routing) % number_of_primary_shardsrouting 是一个可变值,默认是文档的 _idcoordinating node会进行路由,将请求转发给其他DataNode(对应某个primary shard,假如主分片在Node1节点上)
Node1上的Primary Shard处理请求,写入数据到索引库中,并将数据同步到其他的Replica Shard中
Primary Shard 和 Replica Shard都保存完文档后,返回客户端。
文档检索
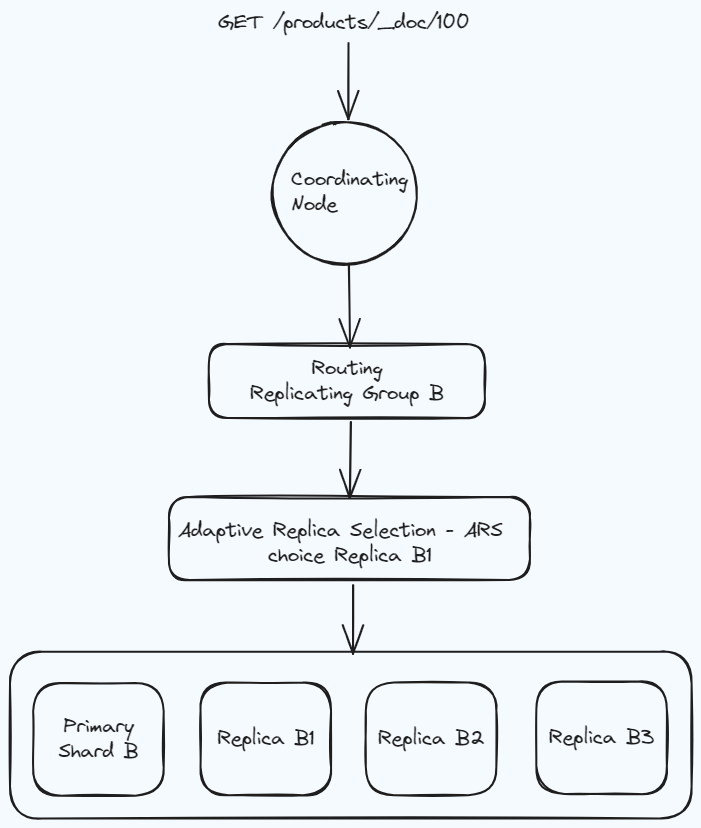
假如选择了Node2,此时Node2称为coordinating node(协调节点)
协调节点(Coordinating Node)将查询请求广播到每一个数据节点,这些数据节点的分片会处理该查询请求。
每个分片进行数据查询,将符合条件的数据放在一个优先队列中,并将这些数据的文档ID、节点信息、分片信息返回给协调节点。
协调节点将所有的结果进行汇总,并进行全局排序。
协调节点向包含这些文档ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据返回给客户端
Elasticsearch 使用一种称为自适应副本选择 (ARS) 的机制选择最佳分片副本,以缓解工作负载的增长。
应用场景
- 大规模数据搜索:当需要对大量文本数据进行快速、高效的搜索时,全文搜索引擎是一个理想的选择。它们能够处理数百万或数十亿条记录,并提供实时搜索结果。如文档文章、日志数据、社交媒体数据等
- 复杂查询需求:如果你需要执行复杂的查询操作,如模糊搜索、范围搜索、布尔搜索等,全文搜索引擎提供了强大的查询语法和功能,可以满足这些需求
- 实时数据分析:全文搜索引擎不仅可以用于搜索,还可以用于实时数据分析和聚合。你可以通过聚合、过滤和分组等功能来获取有关数据集的统计信息和洞察
- 分布式和可扩展性:全文搜索引擎通常是分布式的,可以水平扩展以处理大量的数据和请求。它们具有高可用性和容错性,可以在集群中自动分配和复制数据

