
Redis缓存设计
Redis缓存
前言
Redis作为缓存使用,不仅能加速读写速度,还能降低后端负载。
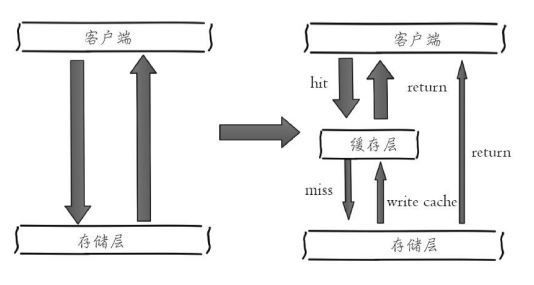
缓存更新策略
缓存中的数据会和数据源中的真实数据有一段时间窗口的不一致,需要利用某些策略进行更新。下面将分别从使用场景、一致性、开发人员开发/维护成本三个方面介绍三种缓存的更新策略。
LRU/LFU/FIFO算法剔除
剔除算法通常用于缓存使用量超过了预设的最大值时候,如何对现有的数据进行剔除。但是要清理哪些数据是由具体算法决定。超时剔除
超时剔除通过给缓存数据设置过期时间,让其在过期 时间后自动删除,例如Redis提供的expire命令。如果业务可以容忍一段时间内,缓存层数据和存储层数据不一致,那么可以为其设置过期 时间。
主动更新
应用方对于数据的一致性要求高,需要在真实数据更新后,立即更新缓存数据。例如可以利用消息系统或者其他方式通知缓存更新。
三种缓存更新策略对比如下:
| 策略 | 一致性 | 维护成本 |
|---|---|---|
| LRU/LFU/FIFO算法剔除 | 最差 | 低 |
| 超时剔除 | 较差 | 较低 |
| 主动更新 | 强 | 高 |
缓存读写策略
以标准的“缓存 + 数据库”的场景为例,剖析经典的缓存读写策略以及它们适用的场景。在日常的工作中根据不同的场景选择不同的读写策略。
Cache Aside(旁路缓存)策略
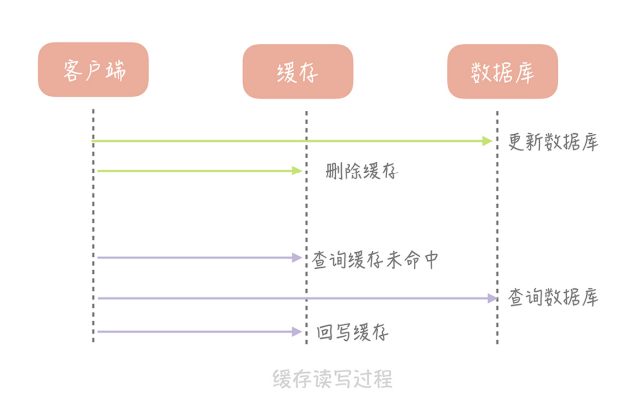
这个策略数据以数据库中的数据为准,缓存中的数据是按需加载的。它可以分为读策略和写策略,其中读策略的步骤是:
- 从缓存中读取数据;
- 如果缓存命中,则直接返回数据;
- 如果缓存不命中,则从数据库中查询数据;
- 查询到数据后,将数据写入到缓存中,并且返回给用户。
写策略的步骤是:
- 更新数据库中的记录;
- 删除缓存记录。
Cache Aside 存在的最大的问题是当写入比较频繁时,缓存中的数据会被频繁地清理,这样会对缓存的命中率有一些影响。如果你的业务对缓存命中率有严格的要求,那么可以考虑两种解决方案:
- 一种做法是在更新数据时也更新缓存,只是在更新缓存前先加一个分布式锁,因为这样在同一时间只允许一个线程更新缓存,就不会产生并发问题了。当然这么做对于写入的性能会有一些影响;
- 另一种做法同样也是在更新数据时更新缓存,只是给缓存加一个较短的过期时间,这样即使出现缓存不一致的情况,缓存的数据也会很快地过期,对业务的影响也是可以接受。
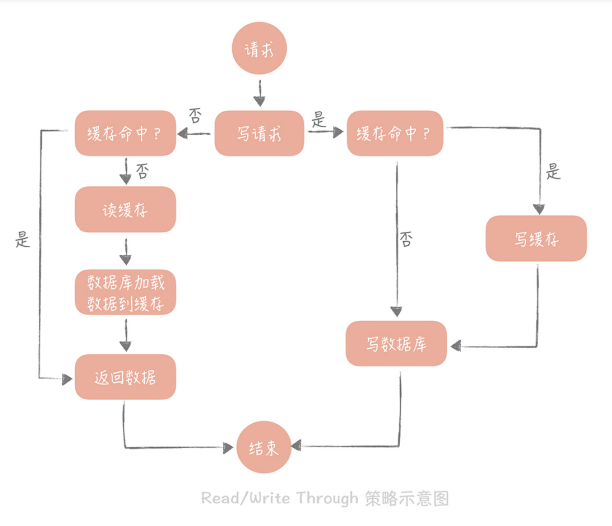
Read/Write Through(读穿 / 写穿)策略
这个策略的核心原则是用户只与缓存打交道,由缓存和数据库通信,写入或者读取数据。
(1)Write Through 的策略是这样的:先查询要写入的数据在缓存中是否已经存在,如果已经存在,则更新缓存中的数据,并且由缓存组件同步更新到数据库中,如果缓存中数据不存在,我们把这种情况叫做“Write Miss(写失效)”。
一般来说,我们可以选择两种“Write Miss”方式:一个是“Write Allocate(按写分 配)”,做法是写入缓存相应位置,再由缓存组件同步更新到数据库中;另一个是“Nowrite allocate(不按写分配)”,做法是不写入缓存中,而是直接更新到数据库中。
在 Write Through 策略中,我们一般选择“No-write allocate”方式,原因是无论采用哪 种“Write Miss”方式,我们都需要同步将数据更新到数据库中,而“No-write allocate”方式相比“Write Allocate”还减少了一次缓存的写入,能够提升写入的性能。
(2)Read Through 策略就简单一些,它的步骤是这样的:先查询缓存中数据是否存在,如果 存在则直接返回,如果不存在,则由缓存组件负责从数据库中同步加载数据。
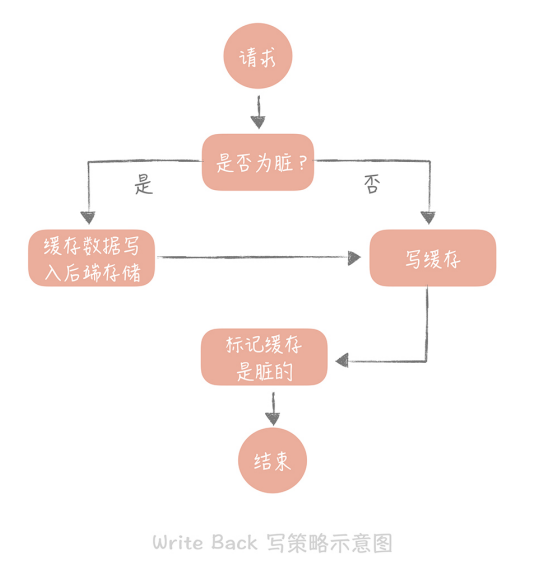
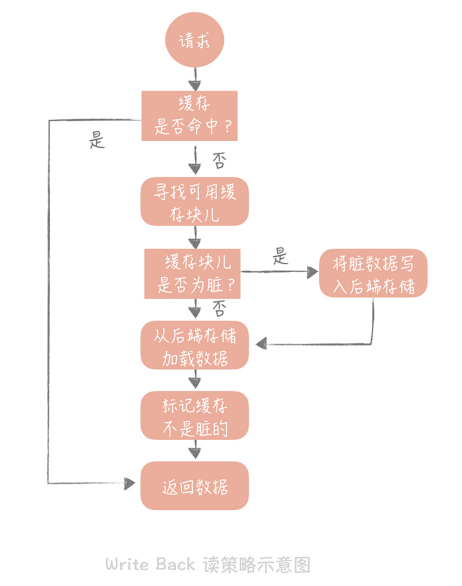
Write Back(写回)策略
这个策略的核心思想是在写入数据时只写入缓存,并且把缓存块儿标记为“脏”的。而脏块只有被再次使用时才会将其中的数据写入到后端存储中。
缓存穿透优化
什么是缓存穿透?
缓存穿透指的是当用户查询数据,在缓存中不存在,并且在数据库也不存在时,导致用户查询这样的数据(或者恶意攻击) 在缓存中找不到对应key的value,每次都需要在数据库中查询一遍,然后返回空值。
其实这就相当于进行了两次无用的查询,这样请求就绕过缓存直接查数据库,对数据库造成了很大的压力。
如何防止缓存穿透
缓存空值
如果DB查询返回数据或者业务结果为空,此时我们仍然将空结果进行缓存,由于空值做了缓存,占用更多的内存空间,所以需要对这些数据设置一个较短的过期时间(不超过五分钟)。
缺点:但如果有大量请求穿透到数据库,然后回写缓存空值,缓存内存有大量的空值缓存,也就会浪费缓存的存储空间,如果缓存空间被占满了,还会剔除掉一些已经被缓存的信息,反而会造成缓存命中率的下降。 所以这个方案,在使用的时候应该评估一下缓存容量是否能够支撑。
布隆过滤器拦截
在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截,从而避免了对底层存储系统的查询压力。(即位图形式,每一个经过hash后存在bit位中,bit位是1代表存在,0代表不存在)
缺点:
tips:GitHub上已经开源了类似的方案,可以进行参考:https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter。
两种方案对比如下:
| 方案 | 适用场景 | 维护成本 |
|---|---|---|
| 缓存空对象 | 数据命中不高、数据频繁变化实时性高 | 需要过多的缓存空间并且数据不一致 |
| 布隆过滤器 | 数据命中不高、数据相对固定实时性低 | 缓存空间占用小 |
缓存雪崩优化
什么是缓存雪崩?
如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有查询都落在数据库上,就会造成了缓存雪崩。由于原有缓存失效,新缓存未到期间所有原本应该访问缓存的请求都需要去查询数据库,从而对数据库服务CPU和内存造成巨大压力,严重可能会造成数据库服务宕机。
如何防止缓存雪崩
过期时间 + 随机值
要避免给大量的数据设置一样的过期时间,过期时间 = baes 时间+ 随机时间(较小的随机数,比如随机增加 1~5 分钟)。
这样一来,就不会导致同一时刻热点数据全部失效,同时过期时间差别也不会太大,既保证了相近时间失效,又能满足业务需求。
加锁排队
维护一个mutex互斥锁,通过Redis的SETNX命令去设置一把当前业务操作的锁(例如setnx lock_uid_001 value nullValue、setnx lock_white_list value nullValue),只允许一个线程查询数据和写缓存,其他线程如果发现有锁就等待,等解锁后再返回数据。该方案会造成部分请求等待。
双层缓存策略
同一条数据我们可以维护两套缓存,C1为原始缓存,C2为拷贝缓存,当C1失效时,可以读取C2,都不存在时再去访问数据库回设,当然C1缓存失效时间需要设置为短期(如5min),而C2设置为长期(如1天)。这种方式最大缺点就是占用的内存翻倍。
双key
思路和方案2类似,不同的是双key分别缓存过期时间(key-time)和缓存数据(key-data),其中(key-time)的缓存失效时间设置为短期(比如5min),(key-data)的缓存失效时间设置为长期(比如1天)。当第一个线程发现 key-time 过期不存在时,则先更新key-time,然后去查询数据库并更新key-data 的值;当其他线程来获取数据时,虽然第一个线程还没有从数据库查询完毕并更新缓存,但发现key-time存在,会直接读取缓存的旧数据返回。和二级缓存的方案对比,该方案的缓存空间利用率高。
热点key重建优化
什么是热点key?
某个key访问非常频繁,当key失效的时候有大量线程来访问数据库然后再写到缓存,导致负载增加,系统崩溃。
如何优化?
减少热点key的重建次数
互斥锁(mutex key)
此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。(使用setnx命令实现上述功能)

缓存过期时间不设置
缓存过期时间不设置,而是设置在key对应的value里。如果检测到存的时间超过过期时间则异步更新缓存。







