
Redis高可用篇:Cluster 集群原理
为什么需要Cluster
保存大量数据,除了使用大内存主机的方式,我们还可以使用切片集群。俗话说「众人拾材火焰高」,一台机器无法保存所有数据,那就多台分担。
使用 Redis Cluster 集群,主要解决了大数据量存储导致的各种慢问题,同时也便于横向拓展。
两种方案对应着 Redis 数据增多的两种拓展方案:垂直扩展(scale up)、水平扩展(scale out)。
- 垂直拓展:升级单个 Redis 的硬件配置,比如增加内存容量、磁盘容量、使用更强大的 CPU。
- 水平拓展:横向增加 Redis 实例个数,每个节点负责一部分数据。
什么是Cluster集群
Redis 集群是一种分布式数据库方案,集群通过分片(sharding)来进行数据管理(「分治思想」的一种实践),并提供复制和故障转移功能。
将数据划分为 16384 的 slots,每个节点负责一部分槽位。槽位的信息存储于每个节点中。
它是去中心化的,如图所示,该集群有三个 Redis 节点组成,每个节点负责整个集群的一部分数据,每个节点负责的数据多少可能不一样。
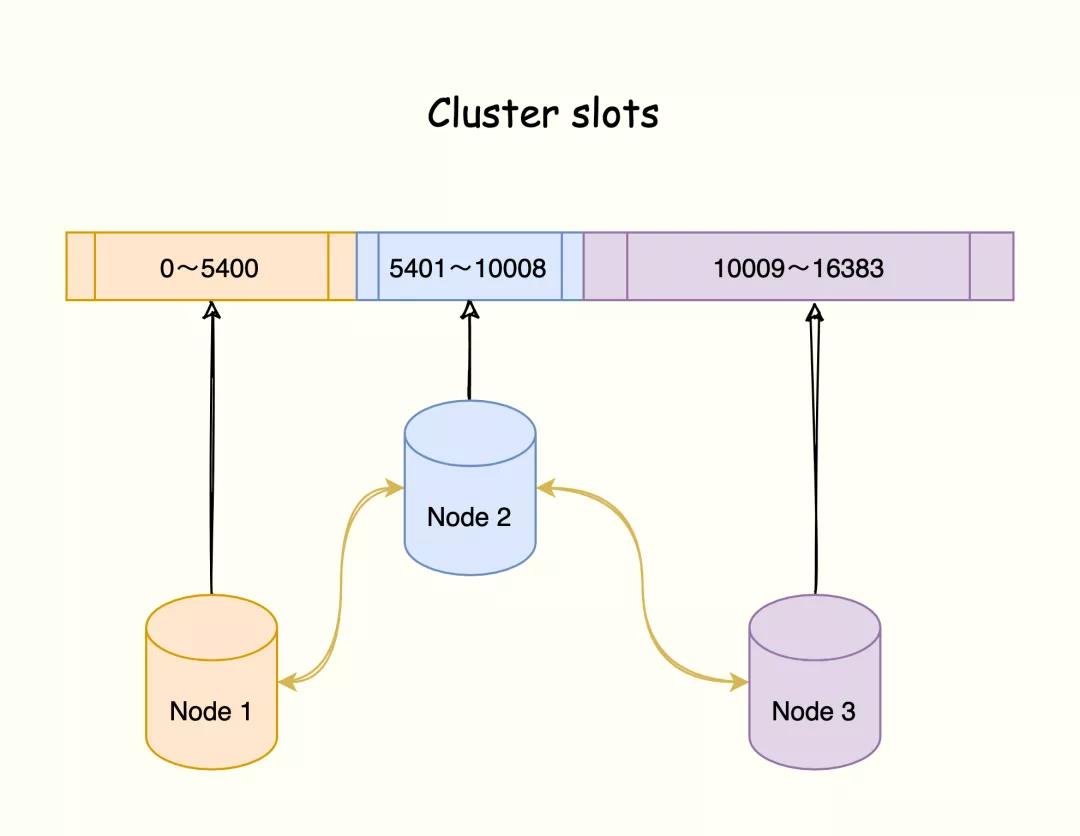
三个节点相互连接组成一个对等的集群,它们之间通过 Gossip协议相互交互集群信息,最后每个节点都保存着其他节点的 slots 分配情况。
Cluster实现原理
Redis 3.0 开始,官方提供了 Redis Cluster 方案实现了切片集群,该方案就实现了数据和实例的规则。Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot),来处理数据和实例之间的映射关系。
将数据分成多份存在不同实例上
集群的整个数据库被分为 16384 个槽(slot),数据库中的每个键都属于这 16384 个槽的其中一个,集群中的每个节点可以处理 0 个或最多 16384 个槽。
Key 与哈希槽映射过程可以分为两大步骤:
- 根据键值对的 key,使用 CRC16 算法,计算出一个 16 bit 的值;
- 将 16 bit 的值对 16384 执行取模,得到 0 ~ 16383 的数表示 key 对应的哈希槽。
Cluster 还允许用户强制某个 key 挂在特定槽位上,通过在 key 字符串里面嵌入 tag 标记,这就可以强制 key 所挂在的槽位等于 tag 所在的槽位。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 胡椒粉的秋天!







