
无题
传统神经网络
大体理解:神经网络有多层,每一层都有一个或多个神经元,每层的神经元与下一层神经元相连,神经元连线之间有一个权重w,整个过程其实就是加权求和+激活+全连接。
训练神经网络的过程:输入一组一维向量数据,随机初始化权重w,数据在每一层都进行加权求和后进行激活,使用损失函数(误差函数)计算出输出与真实输出的差距,然后通过反向传播去更新权重w,使得输出与真实输出相近(损失函数的值变小)。
神经网络剖析:通过升维/降维、放大/缩小、旋转、平移、弯曲这5种对输入空间(输入向量的集合)的操作,完成 输入空间到输出空间的扭曲变换,最终能在扭曲后的空间轻松找到超平面分割空间。
神经网络训练流程过程:http://playground.tensorflow.org/
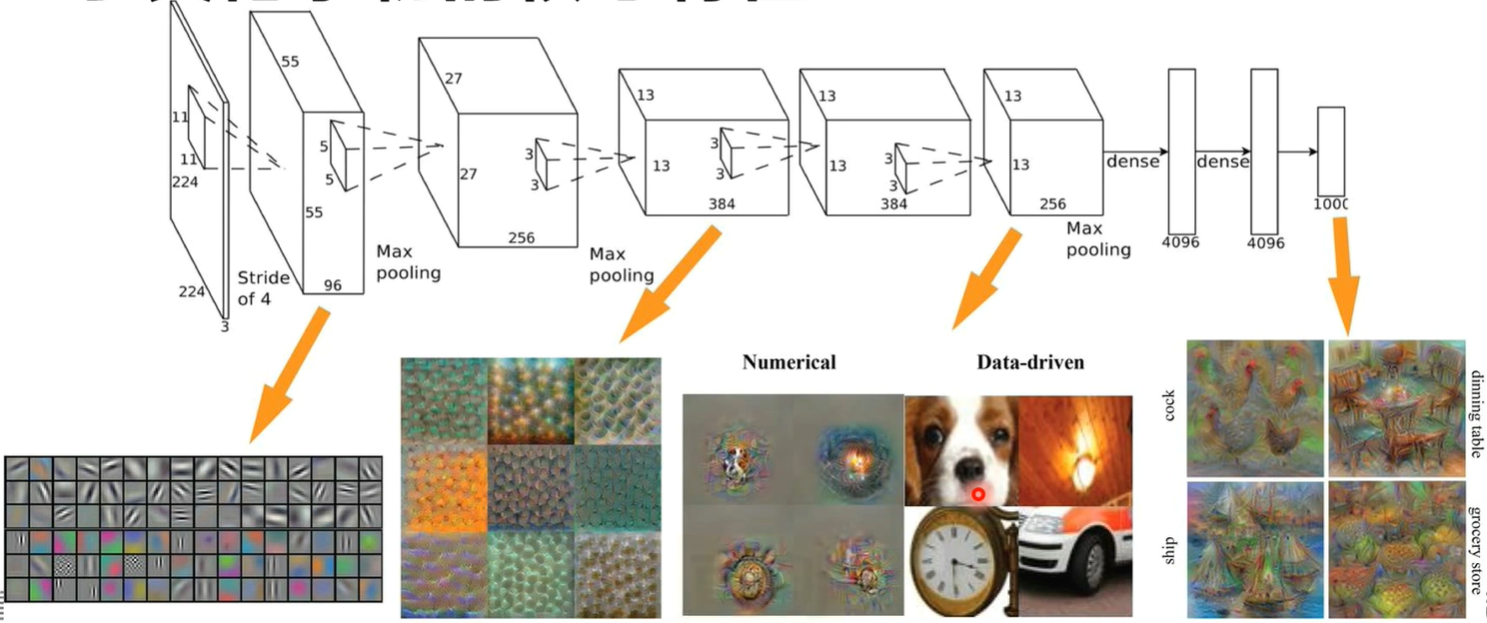
CNN
动态图参考CNN Explainer (poloclub.github.io)
CNN学习和训练的就是卷积核中的所有权重数值。
卷积
计算方法:如果数据是一维的,卷积核也是一维的,如[1,0,-1];数据和卷积核也可以是二维的,这样它就是一个矩阵,例如[[1,-1,0],[0,-1,1],[1,0,-1]],这样的卷积核大小就为3*3,卷积核里面的值其实就是权重;二维卷积过程是数据与卷积核进行加权求和。
卷积作用:卷积用来识别图像里的空间模式,根据不同的卷积核提取不同的图像特征,如线条和物体局部;多层卷积能从图像抽象的特征不断提取到具体的能分辨出来的特征,比如:第一次卷积提取到图像物体的边缘,第二次卷积提取物体纹理,直到提取出具体的物体。
填充padding
步长stride
1*1卷积:它是一种特殊的卷积方式,卷积核大小是1*1,它的主要作用如下:
增加网络深度(增加非线性映射次数)
可以在保持feature map尺度不变的(即不损失分辨率)的前提下大幅增加非线性特性(利用后接的非线性激活函数),把网络做的很深
升维/降维
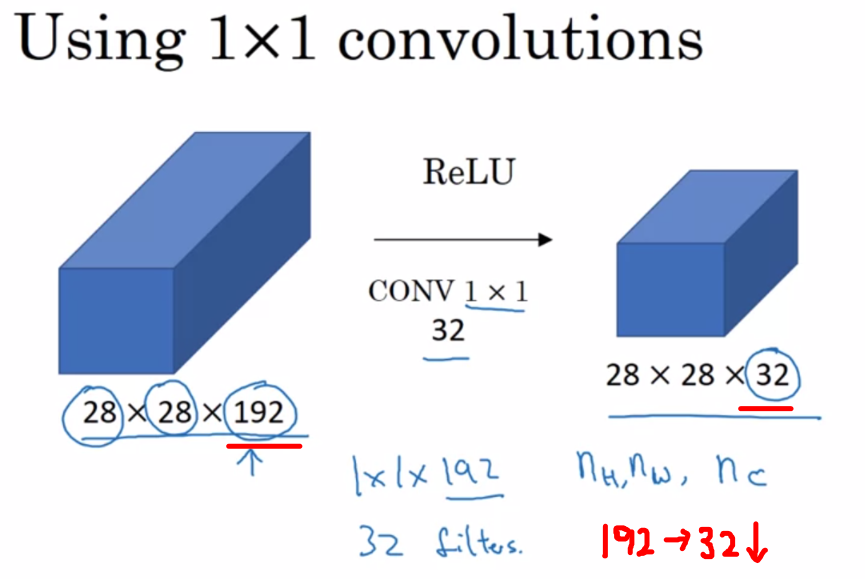
假如输入的feature map的尺寸是28×28×192,卷积核尺寸是1×1×32,经过卷积后,等到的通道数变为32,长宽不变,从而起到降维的作用。
跨通道的信息交互
减少卷积核参数(简化模型)
激活(非线性处理)
对输入进行变换,引入非线性特性;目的是把数据结果变化到我们需要的一个区间,比如一个概率区间,便于决策。
例如: y = 2x,线性关系,引入一个非线性函数,例如激活函数 sigmoid(x) = 1 / (1 + exp(-x)),到的新的输出变量可以表示为y' = sigmoid(2x),通过引入非线性激活函数,我们改变了原始线性函数的形状和性质,这种非线性特性使得模型能够学习和表示更加复杂的模式和关系。
比如图像中的边缘、纹理、形状等特征往往是非线性的,无法用简单的线性关系来表示。
常见的激活函数:
- sigmod函数
- tanh函数
- Relu函数
- ELU函数
- PRelu函数
池化层
作用:对输入数据进行下采样(down sampling),减少数据的空间尺寸,降低计算量,同时保留重要的特征信息。例如:原来4X4的feature map经过池化操作之后就变成了更小的2*2的矩阵;再例如:对一张人物图像下采样(缩小)之后,我们还能认识这个人物图像,因为图像的核心特征还在。这是尺度不变形。
池化的方法:max pooling,即取最大值,以及average pooling,即取平均值。
全连接层
过程:将输入的所有图像的像素值平坦(flatten)排成一列,多维度的向量转换为一维的向量。
作用:卷积和池化层的输出表示了输入图像的高级特征,而全连接层的目的就是为了使用这些自动获取的高级- 特征进行分类识别等学习人物。
传统神经网络和CNN的区别
- 传统神经网络输入都是一维向量,比如图像分类,传统神经网络必须要把多维度的图像信息转换为一维向量才能输入神经网络中,也就是说,传统神经网络会平等的对待每一个像素值;而CNN会通过卷积提取出图像的主要特征,过滤掉不重要的特征,最后通过主要特征进行分类。
批量归一化
在res网络中,提出了BN层。。。。。。。。。。。。。。,Batch Normalization的目的是使一批(Batch)feature map满足均值为0,方差为1的分布规律。
- 批量归一化固定小批量中的均值和方差,然后学习出适合的偏移和缩放
- 可以加速收敛速度,但一般不改变模型精度
其他
数据集通常可以分成两部分:训练数据集用于拟合模型参数,测试数据集用于评估拟合的模型。
过拟合(overfitting):当一个模型在训练集上表现良好,但在测试集时测试时候表现并不好。
词义理解
1、词向量的维度(通常为512)
2、卷积(convolution:本质不变的变换):卷积的本质是滤波(特征提取),操作是加权平均、乘加运算,其目的是提取有用信息。
延伸阅读:在通常的深度学习卷积层,有填充(Padding)、步长(Stride)的概念,这样做的好处是对防止图像边缘信息丢失、图像尺寸的控制更好,这使得操作与二维卷积的经典公式差别更大,但是convolution的本质含义并没有改变。
信号处理领域:卷积就是对信号进行滤波
图像领域:卷积就是对图像特征的提取
3、梯度
梯度是一个矢量,在其方向上的方向导数最大,也就是函数在该点处沿着梯度的方向变化最快,变化率最大。
那么在机器学习中逐步逼近、迭代求解最优化时,经常会使用到梯度,沿着梯度向量的方向是函数增加的最快,更容易找到函数的最大值,反过来,沿着梯度向量相反的地方,梯度减少的最快,更容易找到最小值。
PyTorch的自动微分引擎只能计算标量输出的梯度。换句话说,如果你试图在一个非标量值(如一个张量)上调用.backward(),就会出现这个错误。这是因为梯度是一个向量,不能自动计算一个向量对一个向量的导数,需要将一个向量转换为一个标量值,比如将一个向量的所有元素相加,得到一个标量,然后再计算其梯度。因此,如果你想对一个张量求导,你需要将它的所有元素进行加权平均,得到一个标量输出,然后再计算它的梯度。
∂loss/∂b 和 ∂loss/∂w 就是损失函数关于偏置 b 和权重 w 的梯度,通常简称为梯度。梯度是一个向量,它的每个元素对应一个参数,表示在该参数上增加一个微小的变化会对损失函数产生多大的影响。
反向传播:
在反向传播过程中,我们需要计算损失函数对每个参数的梯度,这需要从损失函数出发,将梯度信息沿着网络层反向传递。具体来说,我们首先计算输出的损失函数关于输出层的输出的梯度,然后将梯度沿着网络层反向传递,一直到输入层。在反向传播的过程中,每个神经元会接收来自上一层神经元的梯度,然后根据链式法则计算本层神经元的梯度,并将梯度传递给下一层。
计算图:
计算图(Computation Graph)是机器学习中一种重要的概念,用于描述计算过程中各个变量之间的依赖关系。
在计算图中,每个节点表示一个变量或操作,每条边表示变量之间的依赖关系。计算图中的计算过程通常分为两个阶段:前向传播和反向传播。在前向传播阶段,从输入节点开始,按照依赖关系依次计算每个节点的值,最终得到输出节点的值;在反向传播阶段,从输出节点开始,按照依赖关系依次计算每个节点的梯度,最终得到输入节点的梯度。这种按照依赖关系计算的过程称为自动微分(Automatic Differentiation),也称为反向传播算法(Backpropagation)。
PyTorch 中的张量(Tensor)和模型(Module)都可以构建计算图,每个张量和模型都是计算图中的一个节点。在进行前向传播和反向传播时,PyTorch 会自动构建计算图,并根据计算图计算每个节点的值和梯度。
计算图是机器学习中重要的概念之一,它可以帮助我们更好地理解模型的计算过程和梯度的计算过程,从而更好地设计和优化机器学习模型。
导数是微积分学中重要的基础概念,简单来讲就是指一个函数在某一点处的变化率。
- 导数 表示 变化率
- 微分 表示 变化量
偏导数指的是多元函数在某一点处关于某一变量的导数。
梯度其实就是一个包含所有偏导数的向量,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向变化最快,变化率最大。
激活函数是非线性的,它的本质是引入非线性
交叉熵
图像的项目跟embedding有什么关系,为什么不需要转换成embedding进行处理
embedding是张量吗
什么是解决非线性问题:例如图像分类、自然语言处理等。
线性问题
损失函数(loss function),或“目标函数”、“代价函数”
如果使用的是回归问题的均方误差(MSE)作为目标函数,就可以根据均方误差的大小来调整模型的参数。
怎么定义目标函数,代码怎么对应
上采样是指将特征图的分辨率还原到原始图片的分辨率大小
安装anaconda更改镜像源
1 | pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple |
向量还可以被用来表示向量空间模型的线性变换。在机器学习中,可以通过矩阵乘法来对向量进行线性变换。这种变换可以用来调整向量的方向和大小,从而使模型能够更好地学习数据。
1 | self.block8 = nn.Sequential(*block8) #星号代表什么 |
1 | netG.train() # 开启训练模式,为什么线性模型不需要训练模式 |
torchvision.transforms.Compose:这个类的主要作用是串联多个图片变换的操作。
1 | import torch |
这个 2x3x4 的张量中的每个数字分别代表着学生成绩的不同信息:
- 第一个维度(axis 0)表示学生的序号,包含两个学生。
- 第二个维度(axis 1)表示科目,包含三个科目:数学、英语和体育。
- 第三个维度(axis 2)表示考试次数,每个学科包含四次考试成绩。
这里,我们使用 PyTorch 的函数 torch.tensor() 来创建了一个 2x3x4 的张量 A,它保存了学生的成绩信息。然后,我们通过索引来获取了该张量中的数据。
A[1][0][:] 表示获取第二个学生的数学成绩的所有考试成绩,我们在第一个维度上使用了索引 1,表示获取第二个学生的信息;在第二个维度上使用了索引 0,表示获取数学这一科目的信息;在第三个维度上使用了:,表示获取该学生在所有数学考试中的成绩。最终返回了一个包含四个元素的一维张量(tensor)。
A[:, 1, 1] 表示获取所有学生在第二次考试中的所有成绩,我们在第一个维度上使用了:,表示获取所有学生的信息;在第二个维度上使用了索引 1,表示获取英语这一科目的信息;在第三个维度上使用了索引 1,表示获取所有学生在第二次考试中的成绩。最终返回了一个包含两个元素的一维张量。

